Cloud Agnostic Service offerings
The Cloud-Agnostic service offering consists of building blocks which are designed to manage containerized data science workloads. The user can deploy, terminate, start and stop their resources via the portal.
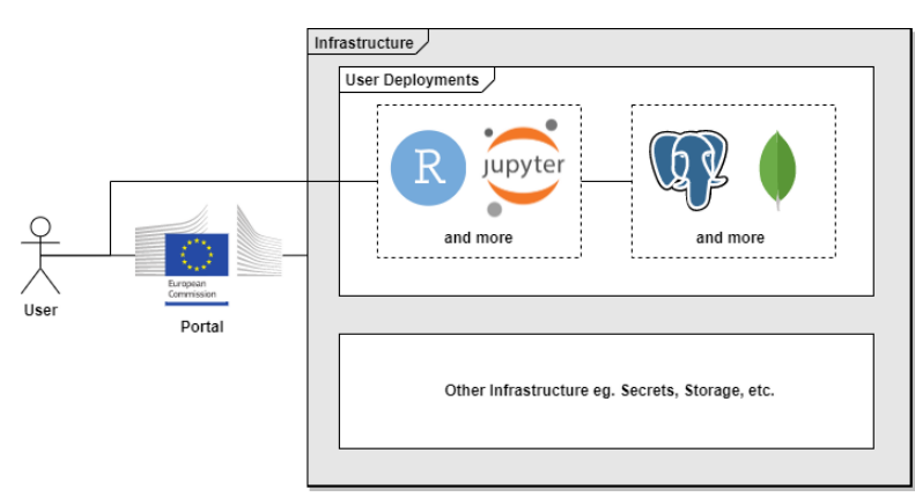
The services included in this offering are presented here below.
Jupyter Lab#
JupyterLab is an interactive, web-based interface for working with data, code, and various types of content. It builds upon the foundation of Jupyter Notebooks, providing an enhanced and versatile environment for data scientists, researchers, and developers to perform a wide range of tasks such as data analysis, data visualization, data modeling, machine learning, and more.
More information can be found here.
R-Studio#
RStudio is an integrated development environment (IDE) specifically designed for the R programming language, which is widely used for statistical analysis, data manipulation, visualization, and modeling. Rstudio provides a user-friendly interface that enhances the R programming experience and supports various tasks associated with data science and statistical computing such as creating, customizing, and viewing data visualizations.
More information can be found here.
PostgreSQL#
PostgreSQL is a versatile and robust open-source relational database management system (RDBMS) suitable for a wide range of applications. Note that PostgreSQL is a type of database system that follows the principles of the relational model and thus stores data in tables with rows and columns, allowing you to define relationships and perform structured queries.
More information can be found here.
MongoDB#
MongoDB is an open-source document-oriented NoSQL database management system designed to handle large volumes of unstructured or semi-structured data such as JSON-Like documents.
More information can be found here.
Apache Airflow#
Apache Airflow is commonly used in data engineering, data science, and business intelligence to automate and schedule tasks involved in data transformation, loading, and analysis. Its ability to manage complex dependencies, parallel execution, and error handling makes it a powerful tool for orchestrating data workflows and managing data pipelines across different systems and technologies.
More information can be found here.
Apache Superset#
Apache Superset is a modern data exploration and visualization platform. It is fast, lightweight, intuitive, and loaded with options that make it easy for users of all skill sets to explore and visualize their data, from simple line charts to highly detailed geospatial charts.
More information can be found here.
Elasticsearch#
Elasticsearch is an open-source, distributed search and analytics engine designed to handle and query large volumes of structured and unstructured data in near real-time. It’s part of the Elastic Stack (formerly known as the ELK Stack), which also includes Logstash for data ingestion and Kibana for data visualization. Elasticsearch is commonly used for full-text search, logging, monitoring, and various analytics tasks.
More information can be found here.
H2O#
H2O is an in-memory platform for distributed, scalable machine learning. H2O uses familiar interfaces like R, Python, Scala, Java, JSON and the Flow notebook/web interface, and works seamlessly with big data technologies like Hadoop and Spark.
More information can be found here.
Kibana#
Kibana is a browser-based analytics and search dashboard for Elasticsearch.
More information can be found here.
Knime#
KNIME is an open-source data analytics and integration platform that allows users to design, execute, and automate a wide range of data processing and analysis tasks. It provides a visual interface for building workflows, allowing users to connect and manipulate data, perform analytics, and create reports without requiring extensive programming knowledge.
More information can be found here.
Metabase#
Metabase is an open-source business intelligence (BI) and data analytics tool designed to simplify the process of querying and visualizing data for non-technical users. It provides an easy-to-use interface for creating and sharing interactive dashboards, reports, and ad-hoc queries, making data insights accessible to a wider audience.
More information can be found here.
MinIO#
MinIO is an open-source, high-performance object storage server that is designed for building scalable and distributed data storage infrastructure. It is API-compatible with Amazon S3, which means that applications and tools that work with Amazon S3 can also work with MinIO without requiring significant modifications. MinIO is particularly well-suited for use cases involving unstructured data, such as images, videos, backups, and log files.
More information can be found here.
Apache Spark#
Apache Spark is an open-source distributed computing framework designed for processing and analyzing large volumes of data in a scalable and efficient manner. It provides a unified platform for batch processing, real-time data streaming, machine learning, graph processing, and interactive querying. Spark allows data to be processed in parallel across a cluster of computers.
More information can be found here.
Virtuoso#
OpenLink Virtuoso is a next-generation Universal Server that facilitates the development and deployment of a new generation of Enterprise-wide, Internet, Intranet, and Extranet-based solutions, transcending prevalent enterprise challenge areas such as Disparate Databases and Data Sources, Web Service Composition, and Business Process Management.
Virtuoso is only for sandboxing through Cloud agnostic offering
More information can be found here.